再來跟大家簡述一下Amazon的首席科學家Nikko Strom今年3月在由西雅圖的美中技術與創先協會(ATI)舉辦的第一屆AI NEXT大會揭密Alexa是怎麼練成的。
一開始,先跟大家提一下,人耳並非隨時都在蒐集語音資訊,真正在聽的時間大約只佔了10%的時間,所以說到了16歲時,一個人大語音訓練時間大概是14,016個小時。

回到了Alexa, Amazon的這個專案團隊將數千個小時的語音訓練儲存資料存到亞馬遜網路服務系統AWS的亞馬遜簡易儲存服務S3並使用彈性雲端運算EC2雲上的分散式GPU集群來訓練深度學習模型。因為數據量太大,該團隊只能採用分散式訓練法(Distributed training),有多台GPU同時運行。
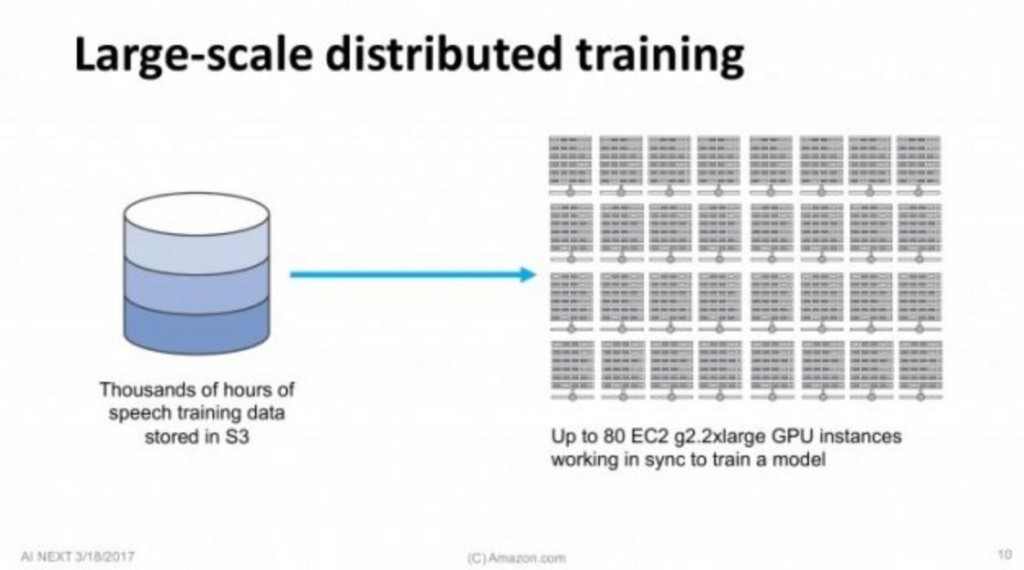
在這過程當中,每個執行序(Worker)都要和其它執行序同步更新幾百兆數據,一秒鐘之內這個過程要發生多次。問題是,這種方法產生了瓶頸,同步更新的數據量太大,限制了訓練無法進一步提升。

這時候Amazon解決方案是:使用逼近演算法(approximations)減少更新規模,壓縮了3個量級。隨著GPU執行續的增加,訓練速度加快。80個GPU執行續對應著大約55萬幀/秒,每秒語音大約包含100幀,也就是說現在這一秒可以處理大約90分鐘的語言。
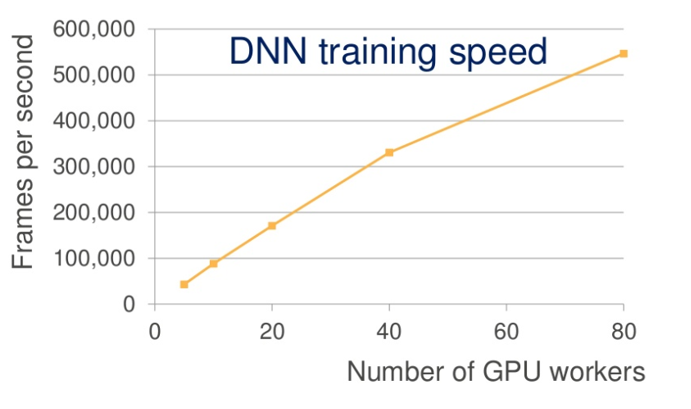
所以說1個人要要花16年的時間來學習1.4萬小時的語音, Amazon 的系統3小時可學完。
此為Alexa大概的深度學習架構
資料來源: Deep Learning in Alexa at AI NEXT conference


